Amazon Data Firehoseは、PostgreSQLやMySQLなどのデータベースから変更をキャプチャし、Amazon S3上のApache Icebergテーブルに更新を複製する新しい機能をプレビューとして発表しました。この機能は、データベースの更新をストリーミングするためのシンプルでエンドツーエンドのソリューションを提供し、トランザクションのパフォーマンスに影響を与えません。ユーザーは数分でData Firehoseストリームを設定し、データベースから変更データキャプチャ(CDC)の更新を配信できます。これにより、さまざまなデータベースからAmazon S3上のIcebergテーブルにデータを簡単に複製し、最新のデータを使用して大規模な分析や機械学習(ML)アプリケーションを実行できます。AWSの企業顧客は通常、トランザクションアプリケーション用に数百のデータベースを使用しています。最新のデータで大規模な分析とMLを実行するには、テーブルにレコードが挿入、変更、または削除されたときなど、データベースに加えられた変更をキャプチャし、データウェアハウスまたはAmazon S3データレイクにApache Icebergなどのオープンソーステーブル形式で更新を配信する必要があります。多くの顧客は、データベースから定期的に読み取るために抽出、変換、読み込み(ETL)ジョブを開発しています。ただし、ETLリーダーはデータベースのトランザクションパフォーマンスに影響を与え、バッチジョブはデータが分析に利用可能になるまでに数時間の遅延を追加する可能性があります。これを軽減するために、顧客はデータベースに加えられた変更をストリーミングしたいと考えており、これはCDCストリームと呼ばれます。この新しいデータストリーミング機能により、Data Firehoseは、データベースからAmazon S3上のApache IcebergテーブルにCDCストリームを取得し、継続的に複製する機能を追加します。ユーザーは、ソースとデスティネーションを指定することでData Firehoseストリームを設定します。Data Firehoseは、初期データスナップショットと、選択されたデータベーステーブルへの後続のすべての変更をデータストリームとしてキャプチャおよび複製します。CDCストリームを取得するために、Data Firehoseはデータベースレプリケーションログを使用し、データベーストランザクションのパフォーマンスへの影響を軽減します。データベース更新の量が変動すると、Data Firehoseは自動的にデータをパーティション分割し、配信されるまでレコードを保持します。ユーザーは容量をプロビジョニングしたり、クラスターを管理したりする必要はありません。Data Firehoseは、初期ストリーム作成中にデータベーステーブルと同じスキーマを使用してApache Icebergテーブルを自動的に作成し、ソーススキーマの変更に基づいてターゲットスキーマを自動的に進化させることもできます。完全に管理されたサービスとして、Data Firehoseはオープンソースコンポーネント、ソフトウェアアップデート、または運用オーバーヘッドの必要性を排除します。
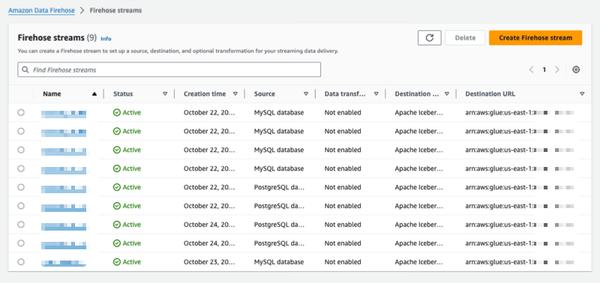
Amazon Data Firehoseを使用してデータベースからApache Icebergテーブルに変更を複製する(プレビュー)
AWS