Amazonは、機械学習(ML)のトレーニングと推論のための最も強力なEC2コンピューティングオプションである、新しいAmazon EC2 Trn2インスタンスとTrn2 UltraServersの提供開始を発表しました。第2世代のAWS Trainiumチップ(AWS Trainium2)を搭載したTrn2インスタンスは、第1世代のTrn1インスタンスと比較して、4倍の速度、4倍のメモリ帯域幅、3倍のメモリ容量を提供します。Trn2インスタンスは、現行世代のGPUベースのEC2 P5eおよびP5enインスタンスよりも30〜40%優れた価格性能比を提供します。各Trn2インスタンスは、16個のTrainium2チップ、192個のvCPU、2 TiBのメモリ、および最大50%低いレイテンシで3.2 TbpsのElastic Fabric Adapter(EFA)v3ネットワーク帯域幅を備えています。新しい製品であるTrn2 UltraServersは、最先端の基盤モデルで最高の性能を発揮するために、高帯域幅、低レイテンシのNeuronLinkインターコネクトで接続された64個のTrainium2チップを備えています。すでに数万個のTrainiumチップがAmazonとAWSのサービスを支えています。例えば、80,000を超えるAWS InferentiaとTrainium1チップが、最近のプライムデーでRufusショッピングアシスタントをサポートしました。Trainium2チップは、Amazon Bedrock上のLlama 3.1 405BおよびClaude 3.5 Haikuモデルのレイテンシ最適化バージョンをすでに強化しています。Trn2インスタンスは米国東部(オハイオ)リージョンで利用可能であり、ML向けのAmazon EC2 Capacity Blocksを使用して予約できます。開発者は、PyTorchやJAXなどのフレームワークであらかじめ設定されたAWS Deep Learning AMIを使用できます。既存のAWS Neuron SDKアプリは、Trn2用に再コンパイルできます。このSDKは、JAX、PyTorch、およびHugging Face、PyTorch Lightning、NeMoなどのライブラリとネイティブに統合されています。Neuronには、NxD TrainingおよびNxD Inferenceによる分散トレーニングと推論の最適化が含まれており、OpenXLAをサポートしているため、PyTorch/XLAおよびJAX開発者はNeuronのコンパイラ最適化を活用できます。
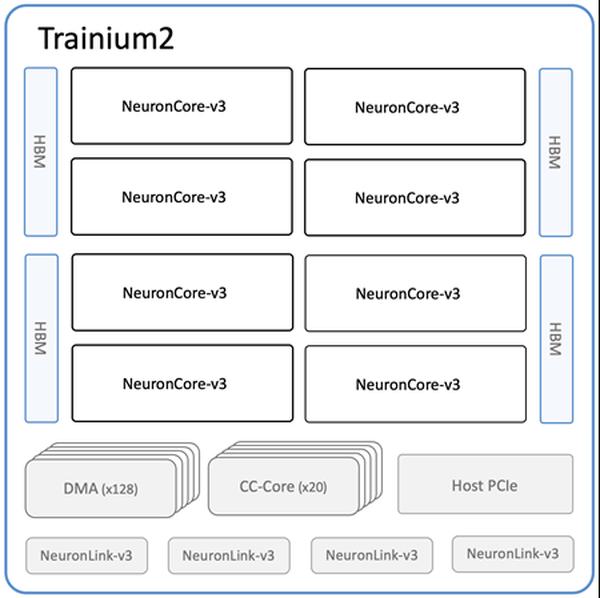
Amazon EC2 Trn2インスタンスとTrn2 UltraServersがAI/MLトレーニングと推論に利用可能に
AWS