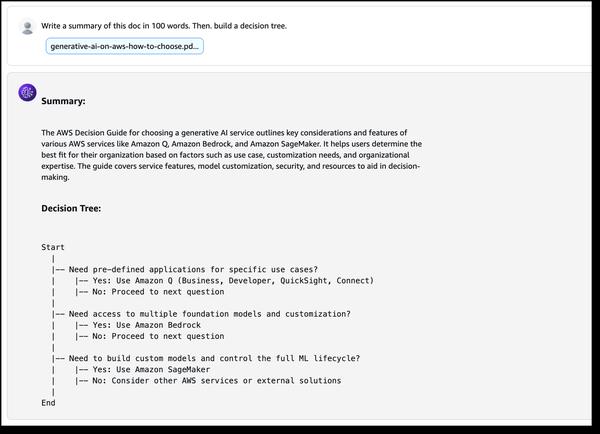
Google Cloudは、大規模言語モデル(LLM)を使用する際に発生する可能性のある429エラー「リソースの枯渇」に対処するためのガイドを公開しました。LLMは大量の計算リソースを必要とするため、スムーズなユーザーエクスペリエンスを提供するにはリソース消費を管理することが重要です。記事では、以下の3つの主要な戦略が紹介されています。
1. **バックオフと再試行:** リソースの枯渇またはAPIの利用不能に対処するために、指数バックオフと再試行ロジックを実装します。過負荷状態のシステムが回復するまで、再試行するたびに待機時間が指数関数的に増加します。
2. **動的共有クォータ:** Google Cloudは、リクエストを行うユーザー間で利用可能な容量を動的に分散することにより、特定のモデルへのリソース割り当てを管理します。これにより、効率が向上し、レイテンシが短縮されます。
3. **プロビジョニングされたスループット:** このサービスを使用すると、Vertex AIで生成AIモデル専用の容量を予約できるため、ピーク需要時でも予測可能なパフォーマンスを確保できます。
記事では、リクエスト量とトークンサイズが大きくなるにつれて、バックオフと再試行のメカニズムを動的共有クォータと組み合わせることが特に重要であると強調しています。LLMアプリケーションの回復力のために、コンシューマ割り当ての上書きやプロビジョニングされたスループットなどの他のオプションについても言及しています。GitHubにあるVertex AIサンプルを使用するか、Google Cloudの初心者向けガイド、クイックスタート、またはスターターパックを活用して、生成AIで構築することを推奨しています。