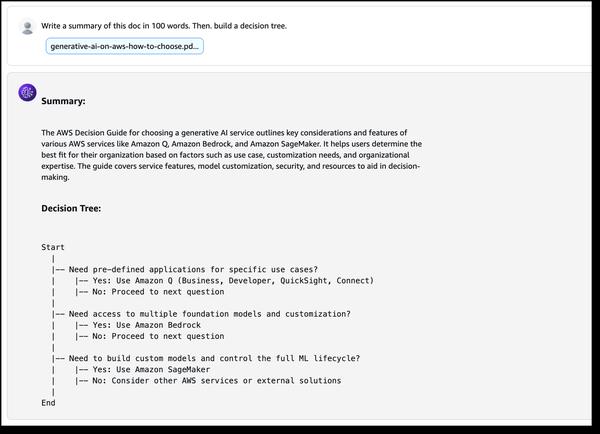
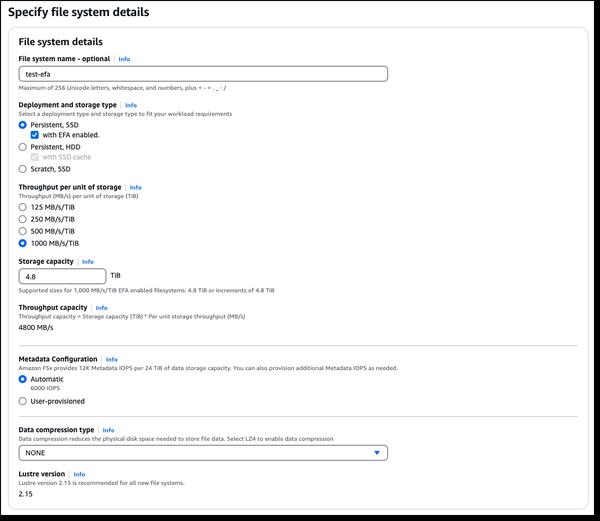
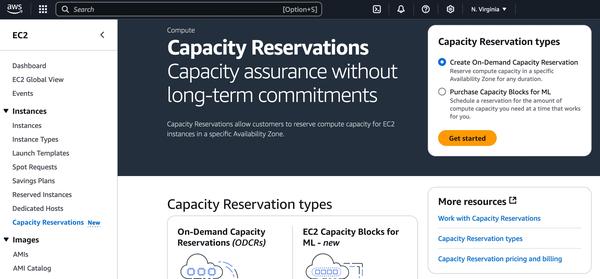
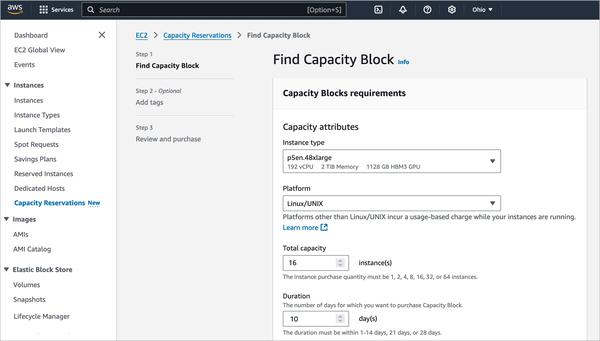
Googleは、Gemmaに焦点を当てた、大規模言語モデルのファインチューニングに関するブログ記事を公開しました。この記事では、データセットの準備から始まり、命令調整済みモデルのファインチューニングまで、プロセス全体の概要を説明しています。
特に興味深いと感じたのは、データの準備とハイパーパラメータの最適化の重要性を強調している点です。これらの側面は、モデルの性能に大きな影響を与える可能性があり、慎重に検討することが不可欠です。
私が仕事でよく目にする課題の一つに、チャットボットが微妙なニュアンスを理解し、複雑な対話を処理し、正確な応答を返すようにすることが挙げられます。このブログ記事で概説されているアプローチは、この問題に対する有望な解決策を提供しているようです。
ハイパーパラメータのチューニングプロセスについて、さらに詳しく知りたいと思います。例えば、具体的にどのパラメータを調整し、どのように最適な値を決定したのでしょうか?この側面に関するより詳細な議論は、非常に参考になるでしょう。
全体的に見て、このブログ記事は非常に有益であり、大規模言語モデルのファインチューニングに関する有用な概要を提供していると感じました。この情報は、チャットボットやその他の言語ベースのアプリケーションを構築しようとしている人にとって、貴重なものであると思います。