Amazon Bedrockは、生成AIアプリケーションのテストと改善を効率化する、新しいRAG評価とLLM-as-a-judge機能を発表しました。Amazon Bedrock Knowledge BasesはRAG評価をサポートするようになり、知識ベースの自動評価を実行してRetrieval Augmented Generation (RAG) アプリケーションを評価、最適化できるようになりました。評価プロセスでは、大規模言語モデル (LLM) を使用して評価指標を計算します。これにより、さまざまな構成を比較し、ユースケースに必要な結果を得るために設定を調整できます。Amazon Bedrock Model EvaluationにはLLM-as-a-judgeが含まれるようになり、人間が評価を行う場合に比べてわずかなコストと時間で、人間のような品質で他のモデルをテストおよび評価できるようになりました。これらの機能により、AIアプリケーションの迅速かつ自動化された評価が提供され、フィードバックループが短縮され、改善が加速されます。評価では、正確性、有用性、責任あるAI基準(回答拒否や有害性など)といった複数の品質次元が評価されます。評価結果は、各スコアの自然言語による説明を0から1に正規化して提供し、解釈を容易にします。ルーブリックとジャッジプロンプトは、透明性を高めるためにドキュメントに公開されています。
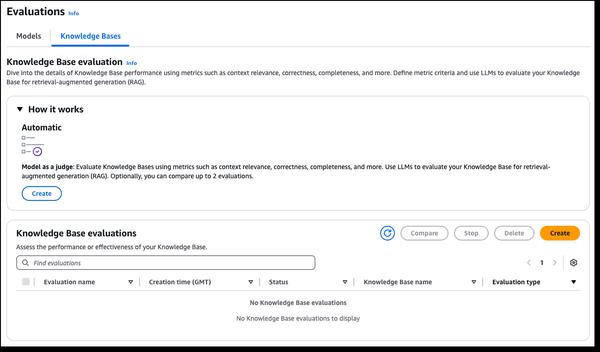
Amazon Bedrockの新しいRAG評価とLLM-as-a-judge機能
AWS