Meta社は、強化された機能、より広範な適用性、そしてマルチモーダル画像サポートを備えた画期的な言語モデルファミリーであるLlama 3.2モデルをAmazon Bedrockでリリースしました。このリリースは、大規模言語モデル(LLM)における大きな進歩を表し、さまざまなユースケースにおいて強化された機能とより広範な適用性を提供します。
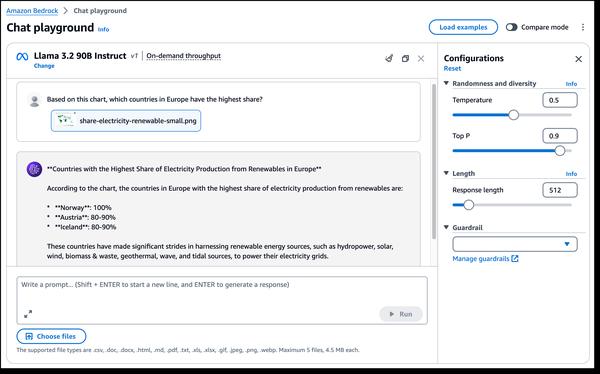
Llama 3.2の最もエキサイティングな側面の1つは、マルチモーダルビジョン機能の導入です。新しい90Bおよび11Bモデルは、画像理解と視覚的推論向けに設計されており、画像キャプション、画像テキスト検索、視覚的な質問応答などのアプリケーションの可能性を広げます。これらの機能は、さまざまな分野において、私たちが画像と対話し、画像を利用する方法に革命をもたらす可能性があります。
さらに、Llama 3.2は、エッジデバイスに適した軽量モデルを提供します。1Bおよび3Bモデルは、レイテンシの短縮とパフォーマンスの向上により、リソース効率が高くなるように設計されており、限られた機能を持つデバイス上のアプリケーションに最適です。これは、モバイルデバイス上で、よりインテリジェントなAI搭載のライティングアシスタントやカスタマーサービスアプリケーションの開発につながる可能性があります。
さらに、Llama 3.2は、標準ツールチェーンコンポーネントとエージェントアプリケーションを構築するための標準化されたインターフェースであるLlama Stack上に構築されており、構築と展開がこれまで以上に容易になります。これは、開発者にLlamaモデルをアプリケーションに統合するための標準化された効率的な方法を提供します。
全体的に見て、Llama 3.2のリリースは、大規模言語モデルの分野における重要な前進を示しています。その強化された機能とより広範な適用性は、画像理解と視覚的推論からエッジアプリケーションまで、幅広いユースケースの可能性を広げます。生成AIテクノロジーの進化が続くにつれて、Llama 3.2のようなモデルから、さらなる革新と変革的なアプリケーションが期待できます。